
AWS Glue DataBrew
Core Concepts
Dataset
Dataset simply means a set of data—rows or records that are divided into columns or fields. When you create a DataBrew project, you connect to or upload data that you want to transform or prepare. DataBrew can work with data from any source, imported from formatted files, and it connects directly to a growing list of data stores.
For DataBrew, a dataset is a read-only connection to your data. DataBrew collects a set of descriptive metadata to refer to the data. No actual data can be altered or stored by DataBrew. For simplicity, we use dataset to refer to both the actual dataset and the metadata DataBrew uses.
In DataBrew replication mode, Data Pipes allows the user to prepare or transform the data if DataBrew mode is selected in the pipeline.
Recipe
In DataBrew, a recipe is a set of instructions or steps for data that you want DataBrew to act on. A recipe can contain many steps, and each step can contain many actions. You use the transformation tools on the toolbar to set up all the changes that you want to make to your data. Later, when you're ready to see the finished product of your recipe, you assign this job to DataBrew and schedule it. DataBrew stores the instructions about the data transformation, but it doesn't store any of your actual data. You can download and reuse recipes in other projects. You can also publish multiple versions of a recipe.
Creating a Transformation Pipeline using Glue DataBrew
Once you configure a source and destination as part of a pipeline, if the data source selected is a File based source or a Data Lake source, the “DataBrew” mode would be enabled. Please select the DataBrew mode and configure the Pipeline Domain and Dataset.
The following screen appears after DataBrew mode is selected during the creation of pipeline.
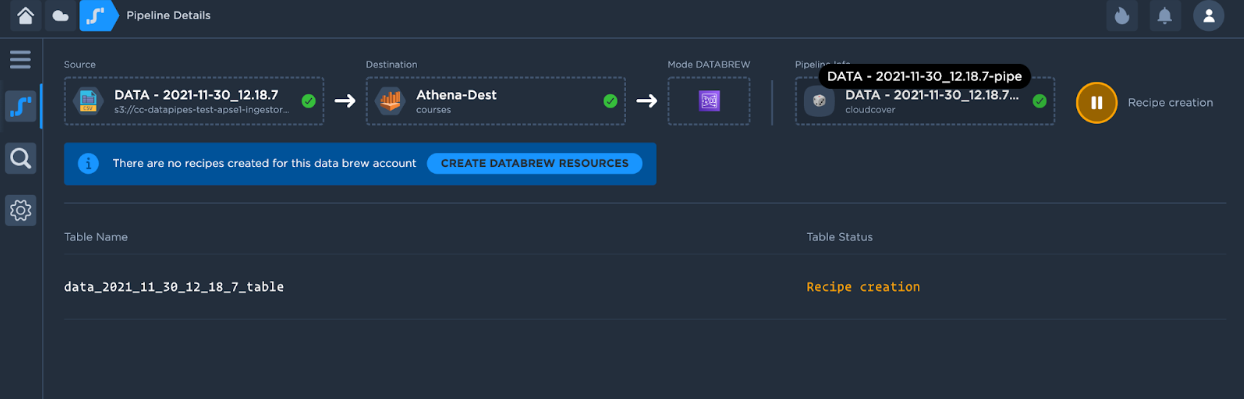
Click on the Create Databrew Resources button, on click of this button, all the resources needed for data preparation are created.
A new tab would open up in the browser using a federated AWS login with Databrew open. Data Pipes creates the necessary Project, adds the dataset to the project and provisions the DataBrew resources for the User. Data users would then be able to cleanse data/apply transformations/Profile the data using the dataset loaded in DataBrew.
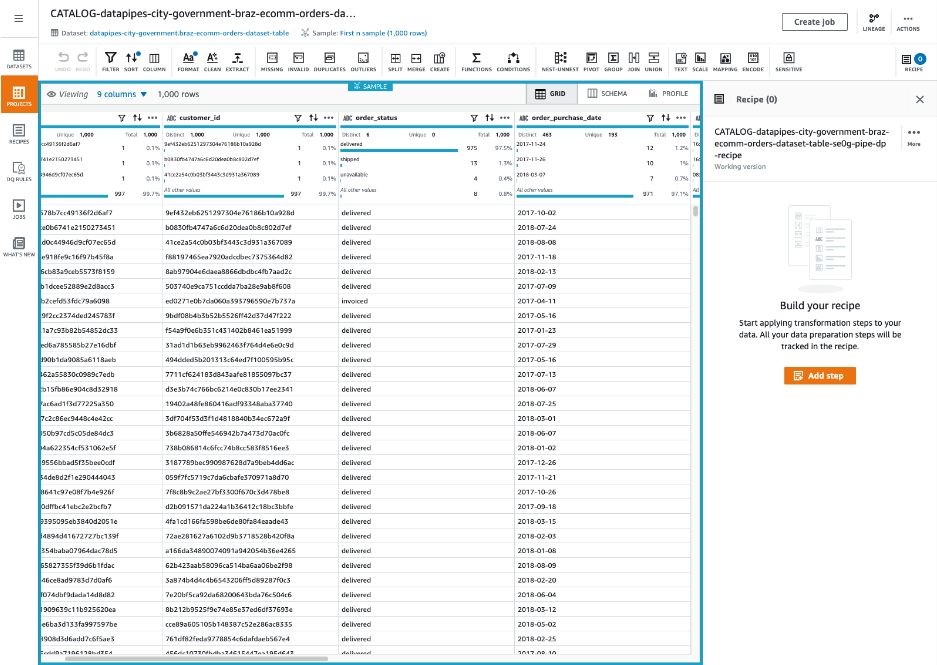
Once the DataBrew resources are created, Create your recipe (A recipe is a set of Data Transformation steps) - once the steps are performed, click on “Publish”
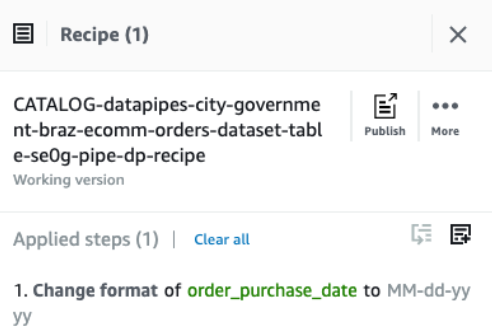
Switch back to the Data Pipes pipeline tab in your browser. Data Pipes should recognize that the user has published a Recipe and should display a button at the bottom right of the screen to start the DataBrew job.
Once the DataBrew job finishes, the transformed data would be loaded into the data lake.
For more information regarding AWS DataBrew, please refer to AWS DataBrew service.