
HTTP based ingestion
With HTTP based ingestion, Data Pipes allows ingestion of data from REST API sources. This guide will provide the prerequisites and the necessary information to configure the REST API source component.
Pre-requisites
Authentication
Data Pipes supports the following methods of Authentication:
No authentication
Bearer Token
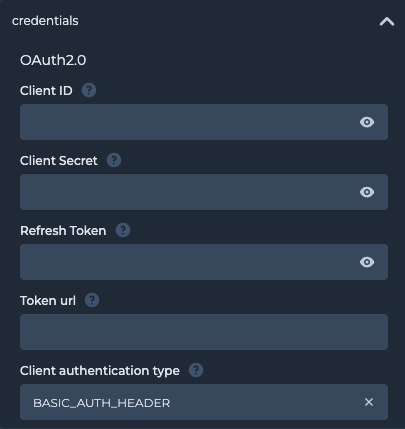
OAuth 2.0 (Client Credentials Flow with Refresh token)
Authentication URL
Request and Response
Request
Methods - Data Pipes supports GET, POST Methods
Headers - Data Pipes supports adding request headers as required by the API in the form of name value pairs
Body - Allows optionally providing a request body string
Query Parameters - Allows optionally providing query parameters. Dynamic parameters in the form of Current date/Timestamp are supported
Pagination
Data Pipes supports pagination using cursors for APIs which return large datasets. Data Pipes implements reading paginated responses in two ways - Link Header/Body
Response
Response should be in JSON format following the json api specifications. Data Pipes can unnest nested json in the destination table provided a record key identifying the records to be loaded is provided in the source connection. In case of an array of objects, only a single level of nesting is supported.
Instructions on creating a new HTTP Ingestion Pipeline
Click on the pipeline icon on the left hand side of the Data Pipes portal
You will be landed on the ingestion pipelines page, where one can see all the pipelines initiated by the user.
Click on the plus icon to create a new pipeline.
Once you click on the plus icon, click on the configure source block to create the source.
From the options choose API
Click on + icon in front of REST
The form will open up like below
Source name: [Mandatory] A unique name to identify the source.
Request type: [Mandatory] REST API request type. GET/POST
API - [Mandatory] Source REST API url [ http://... and https://... supported
Headers: [Optional] If Rest API requires specific headers to be supplied this is where it should be supplied. If Rest API source requires Authentication token or API keys, it can be supplied under this field
Query parameters: [Optional] Query parameters can be supplied in this section.
Record Key: [Optional] Rest API response can have any format. Record key is optional and it represents the key name which holds record(s) the user is interested to write to the data lake. For instance.
Response format | Record Key |
{‘data’:[{object1},{object2},{object3}...] } | data |
[{object1},{object2},{object3}...] | <leave empty> |
{‘data’ : { ‘records’: [{object1},{object2},{object3}...]}} | data.records |
g. [Optional] Set below parameters if your API requires an authentication token which needs to be fetched from another API. Everytime the Ingestion pipeline runs, it will attempt to fetch the fresh token using the below url and supply it to the source API to retrieve the data.
Authorization URL: API source url to fetch the Authorization token from.
Authorization token key: key name from where to retrieve the token value.
Auth API Response format | Token Key |
{“success”:””, “message”:”“ ,”token”: “”} | token |
{“success”:””, “message”:”“ ,”auth_token”: “”} | auth_token |
Authorization Body: If authorization endpoint call requires specific payload such as user name & password, it can be supplied here as a key value pairs.
For OAuth 2.0 based authentication, the following parameters needs to be provided:
h. [Optional] Cursor is needed when the API is returning a paginated response. There are several ways to handle pagination. Data Pipes implements reading paginated responses in two ways. Which can be specified by Cursor_type
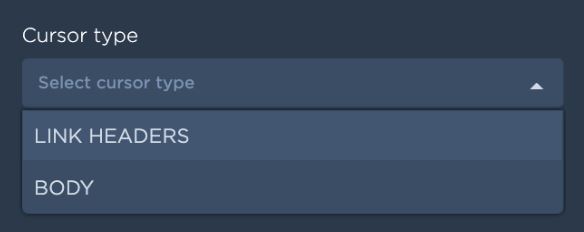
Cursor Type ‘LINK_HEADERS’, If cursor type is chosen as link headers the pagination will be automatically handled by Data Pipes [specs: https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Link ]
Cursor Type is BODY: If cursor type is chosen as body, cursor value can go in either of query params, headers or body in subsequent api calls. In this case, user should give details of how to find cursor value by providing:
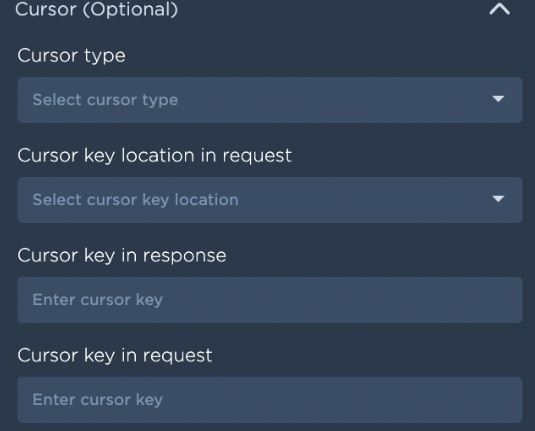
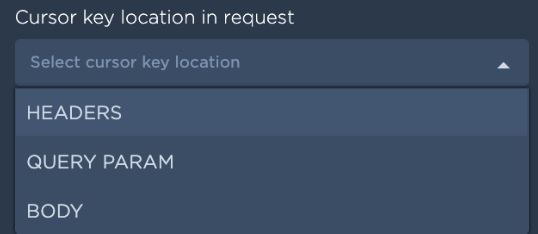
Cursor key location in request: This field represents the location of a cursor key in subsequent api calls. Cursor key can go in either query_params, body or headers
Cursor key in response: This field indicates the key name where the cursor value is will be present in the response.
Cursor key in request: This field represents the name of the cursor key in subsequent requests.
8. Once the source is configured, click on the configure destination option and select the default destination of the data lake.
9. HTTP ingestion supports 2 modes at present:
a. FULL: In this mode, the pipeline will run at a specified frequency and refreshes the entire data
b. INCREMENTAL: In this mode, the pipeline will run at a specified frequency, pick the incremental data and append it to the existing catalog table. For this the input source should support filtering results by timestamp or date.
10. Once the replication mode is selected, click on configure pipeline to provide details like - pipeline name, domain name (where the data is to be loaded), table name.
11. Click on the play button to configure verify the configuration.
a. Enable the scheduler and set the frequency if you want to set up recurring indigestion. If the scheduler is not enabled the pipeline will ingest the data only once.
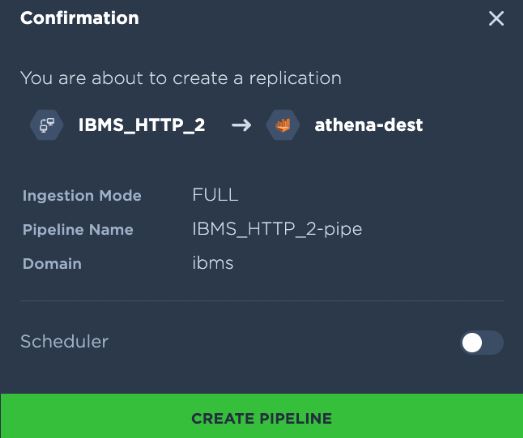
12. Once you create the pipeline after verifying all the details, the “start replication” button will appear at the bottom. Click on it to begin the ingestion.