
Load Data into the Data Lake from CSV
Data ingestion refers to the process of collecting and importing data from various sources into a system or database. In this tutorial, we will be uploading a CSV file (comma-separated values) into the data lake powered by Amazon Athena and AWS S3 storage.
If you need a sample CSV dataset, consider downloading one from https://www.kaggle.com/datasets
Create a new CSV Ingestion Pipeline
Navigate to the Ingestion Pipelines Interface by clicking on the Pipeline icon on the left.
Click on the “+” icon to create a new pipeline.
I
Configure a CSV Data Source
Click on “Configure Source”.
Select a CSV File Source from your computer.
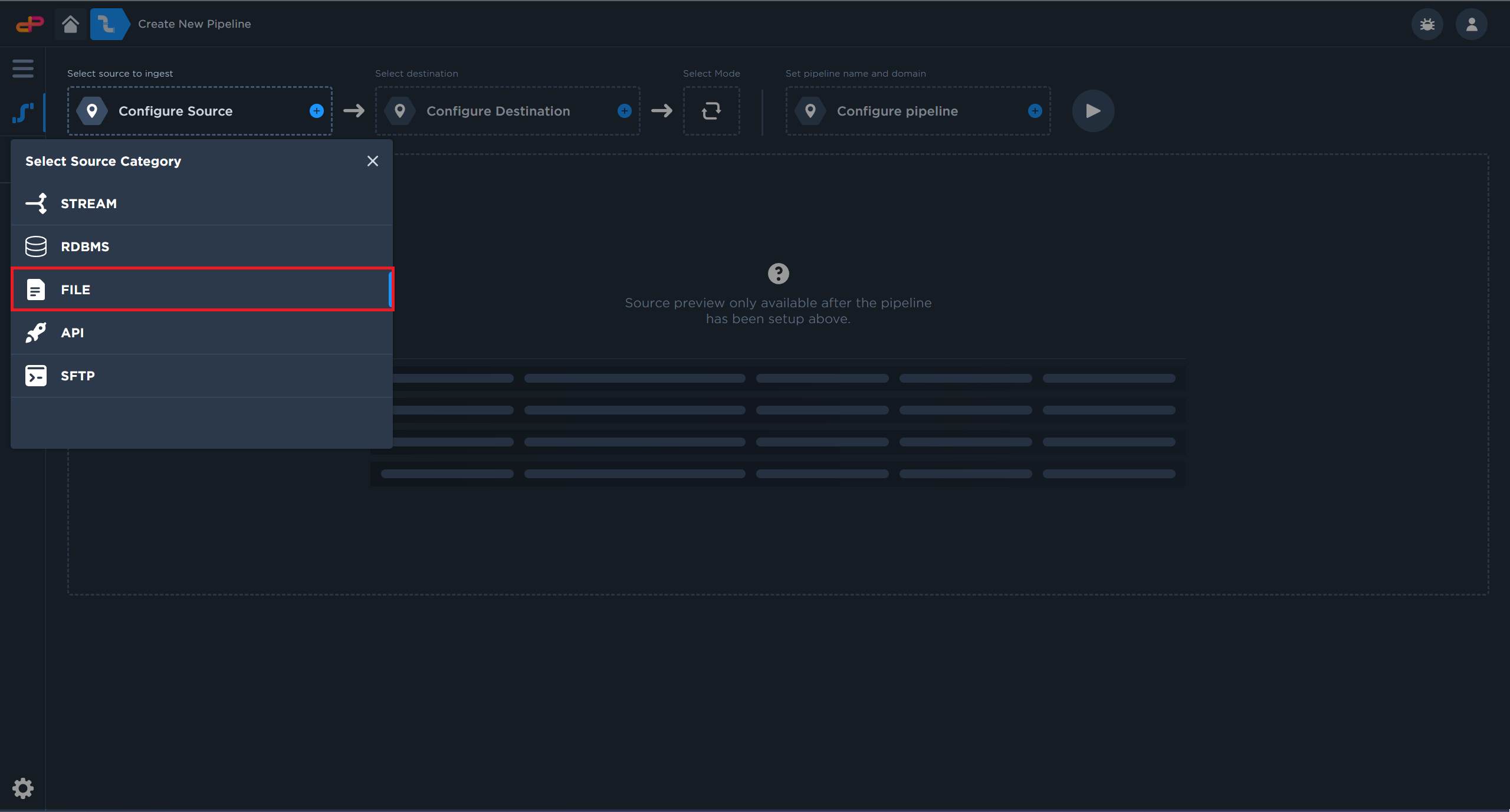
Data Pipes supports various data sources
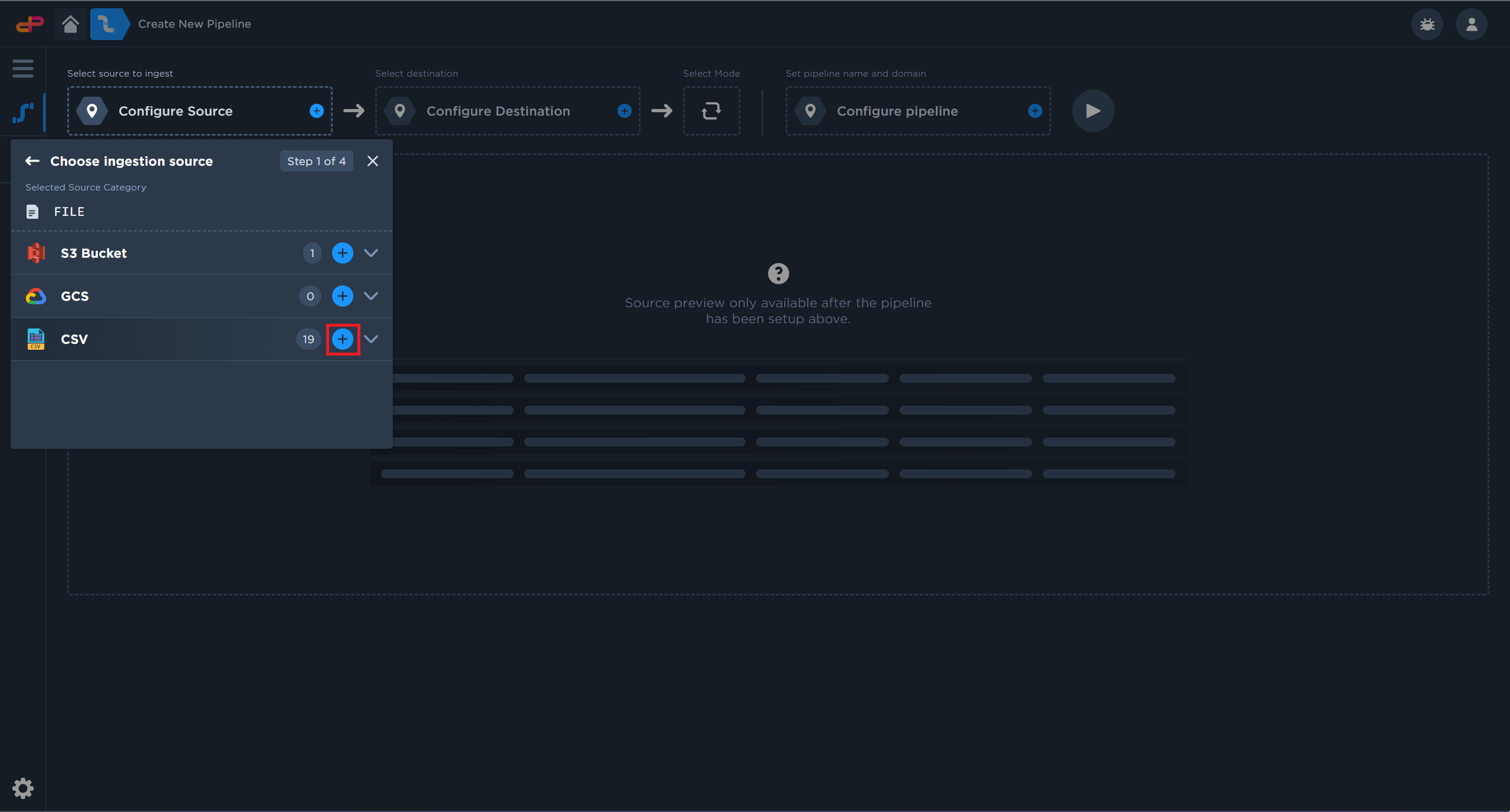
Add a CSV file source for this tutorial
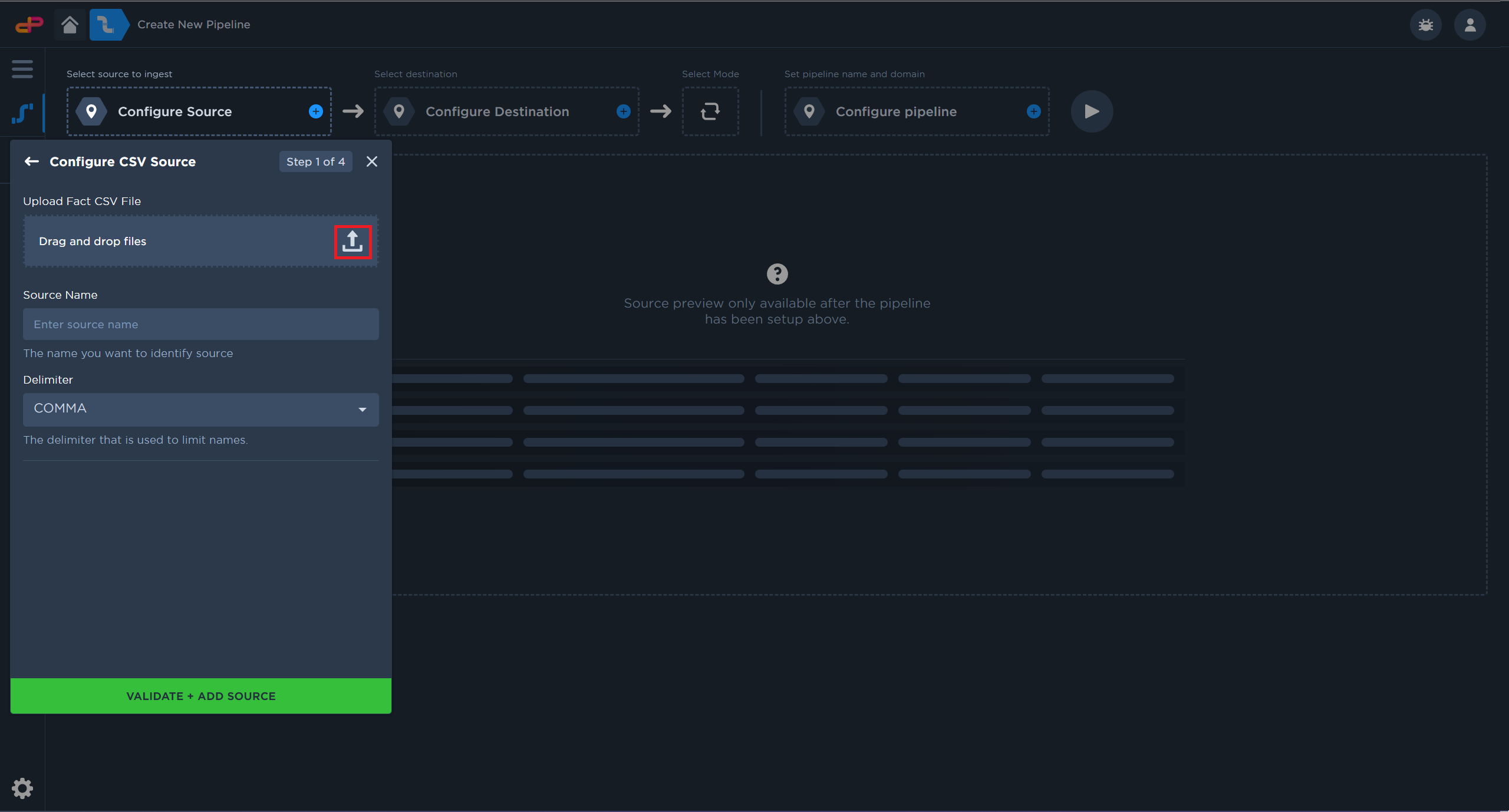
Launch the file selection dialog
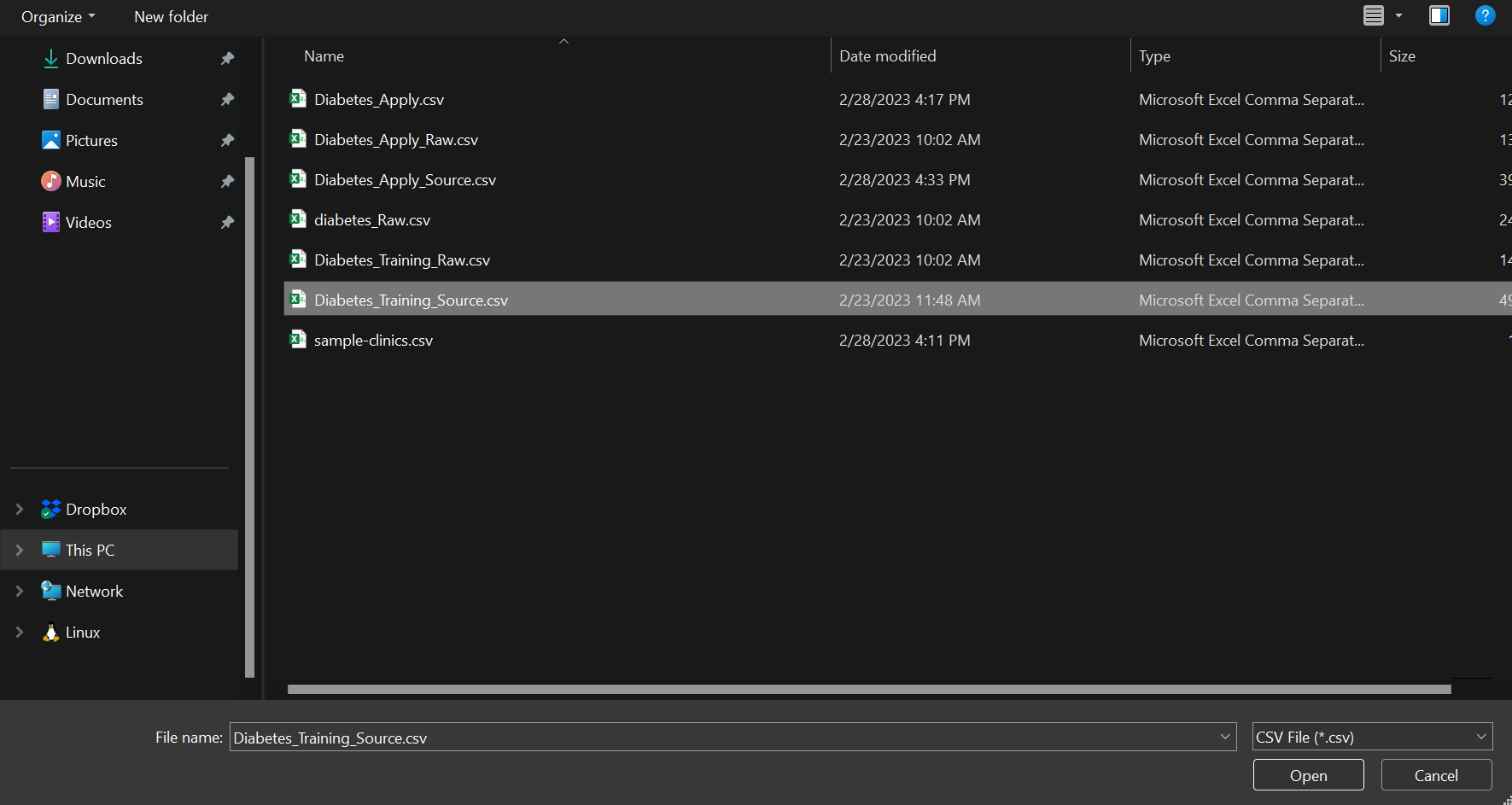
Select a CSV file from your computer
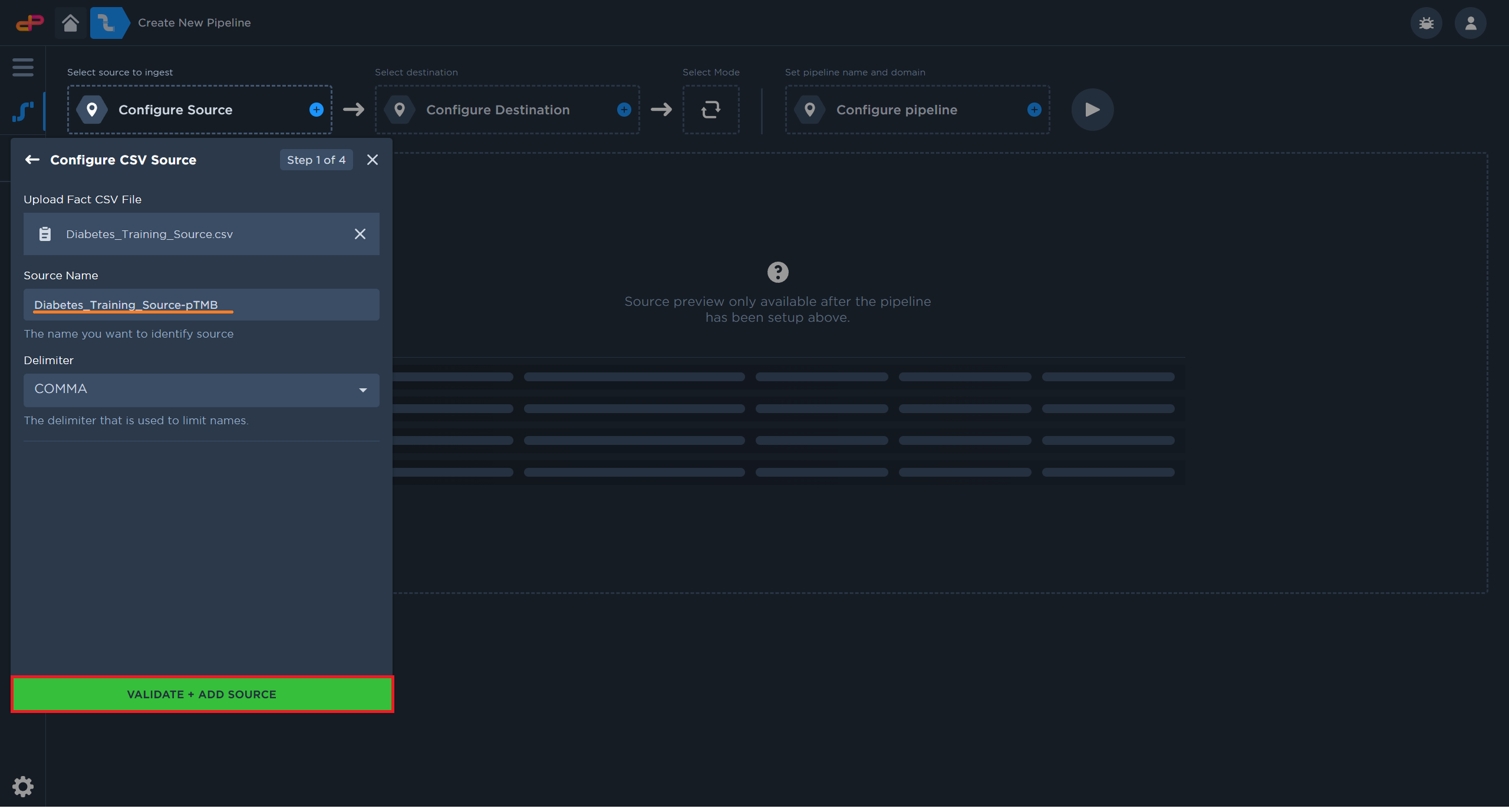
Click on “Add Source” to start the file upload
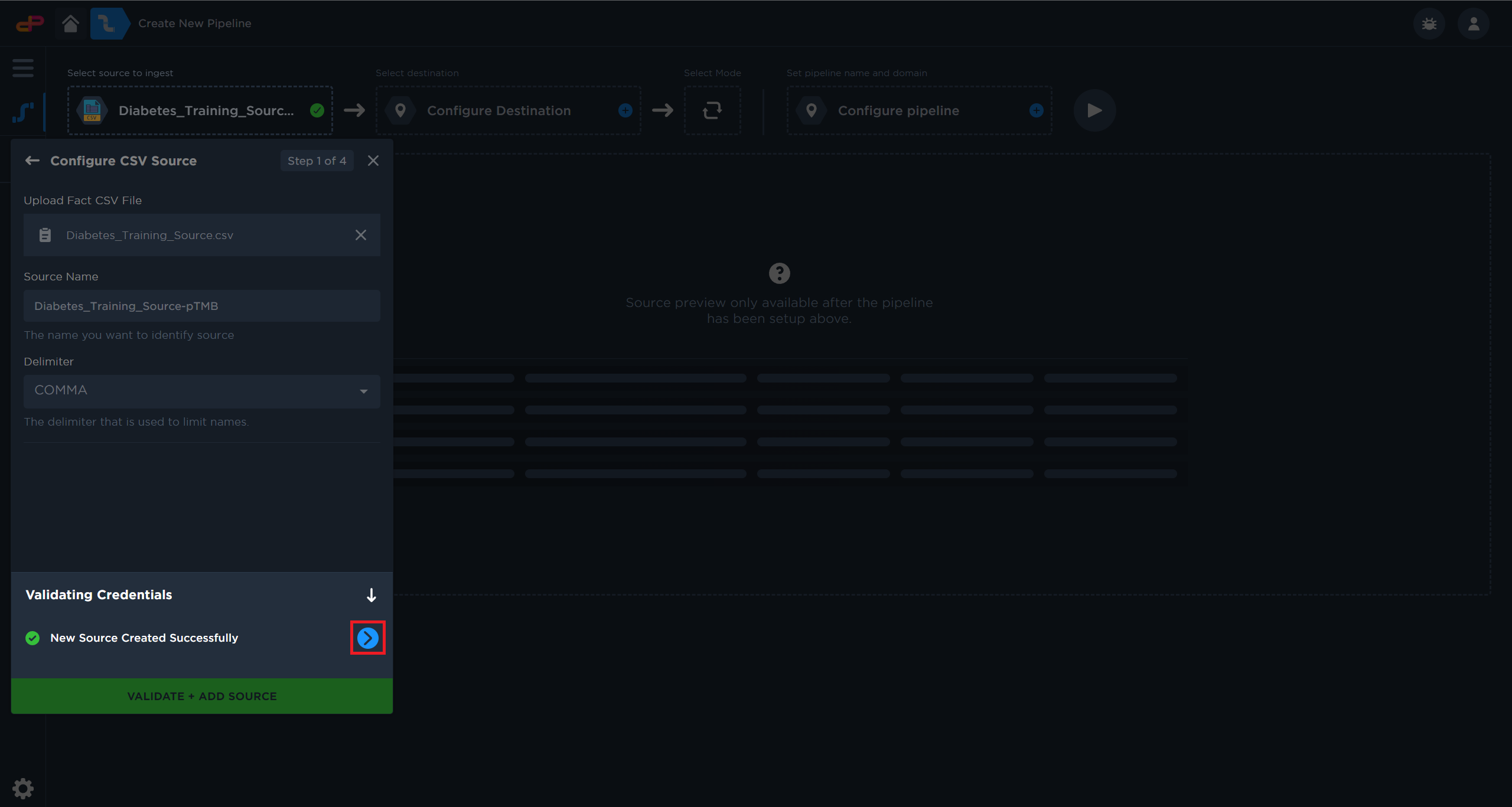
Click on the “Next” arrow to proceed
Configure a Data Lake Destination
Click on “Configure Destination”
Select an existing Amazon Athena as a destination.
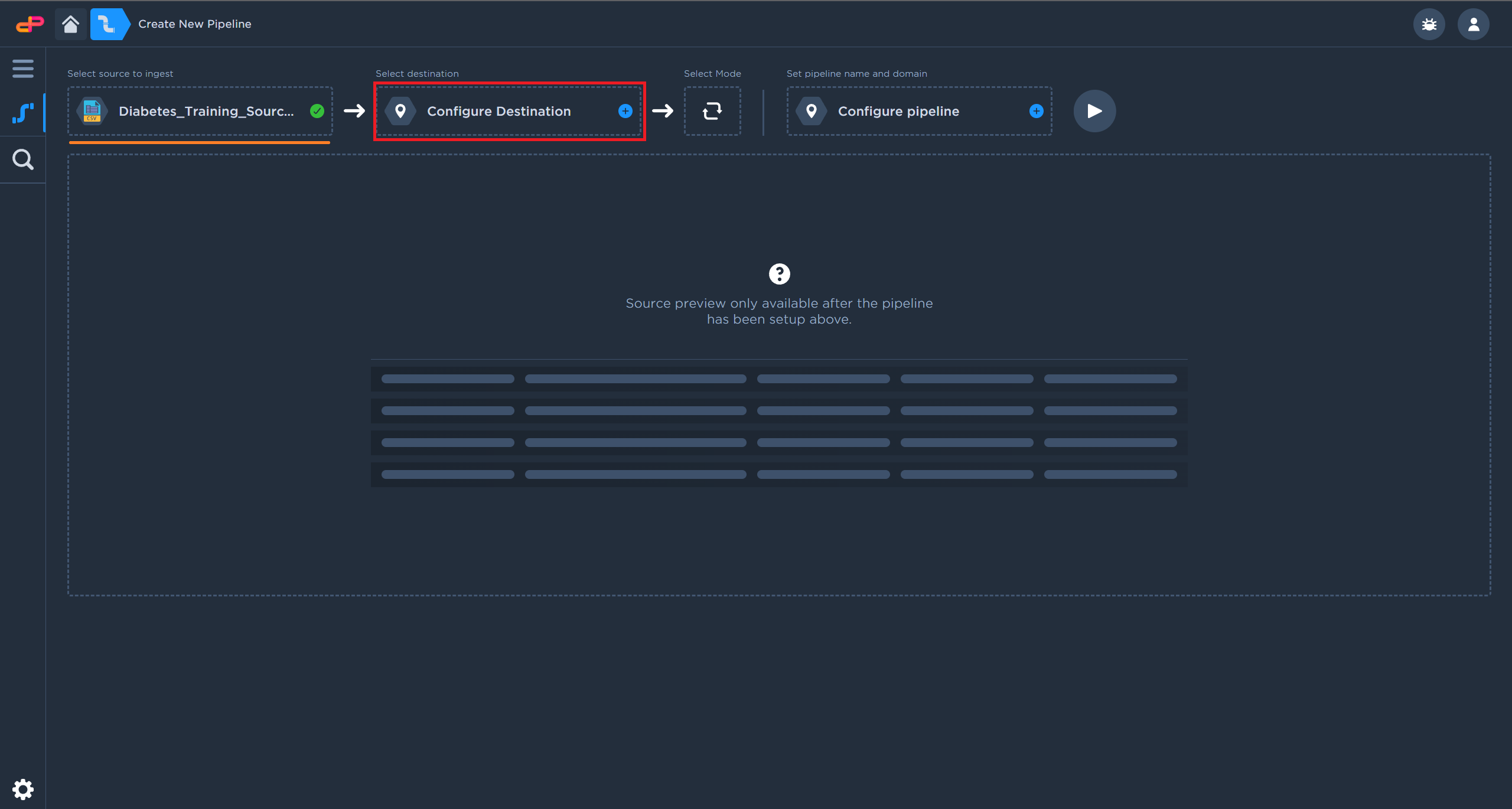
Click on “Configure Destination”
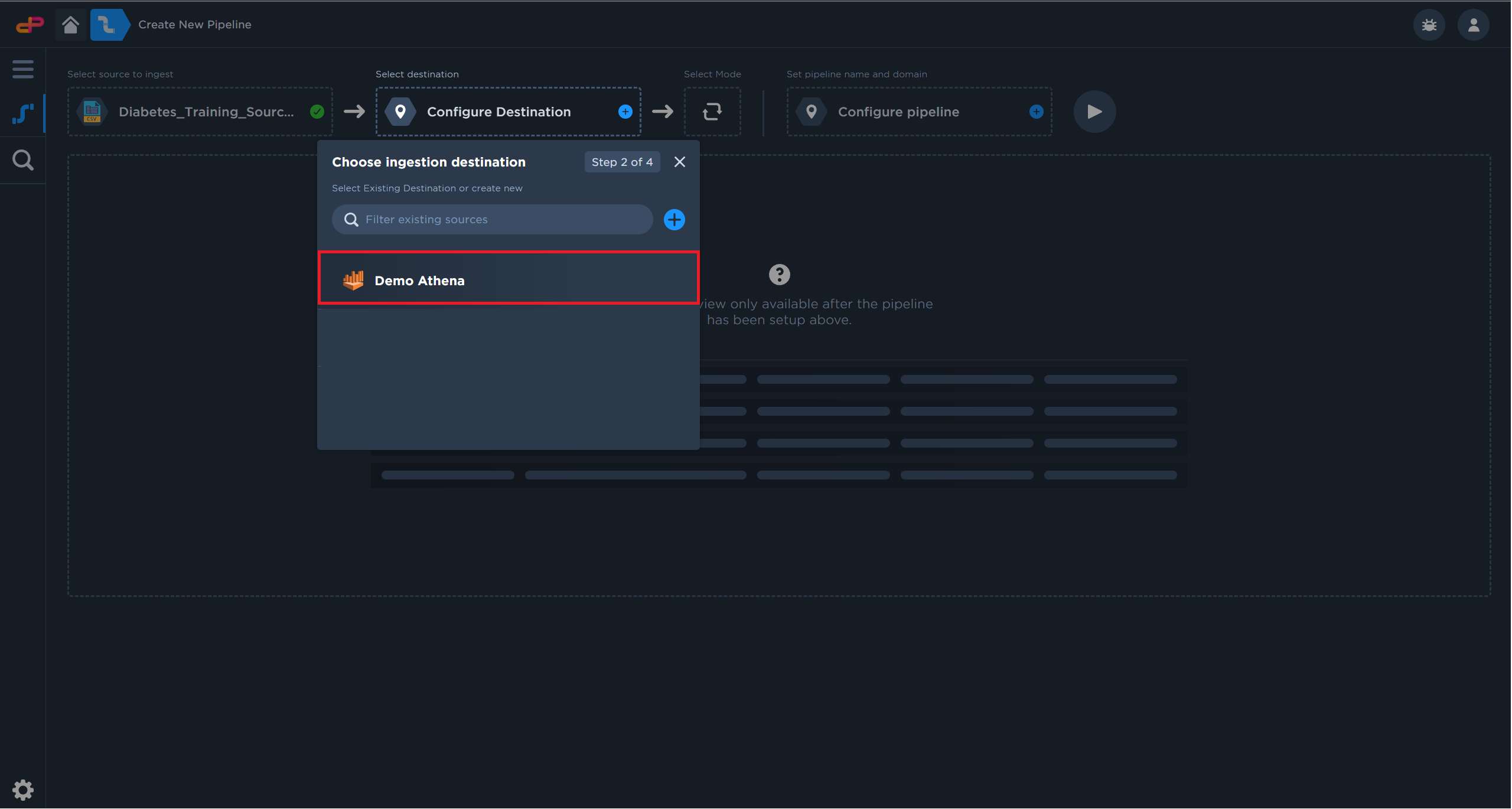
Select an Athena Instance
Configure an Ingestion Mode
Full ingestion mode will create and if applicable, overwrite existing datasets.
Review the list of Ingestion Modes if you are working on production use cases.
Click on “Select Mode” icon.
Select “Full“ ingestion mode.
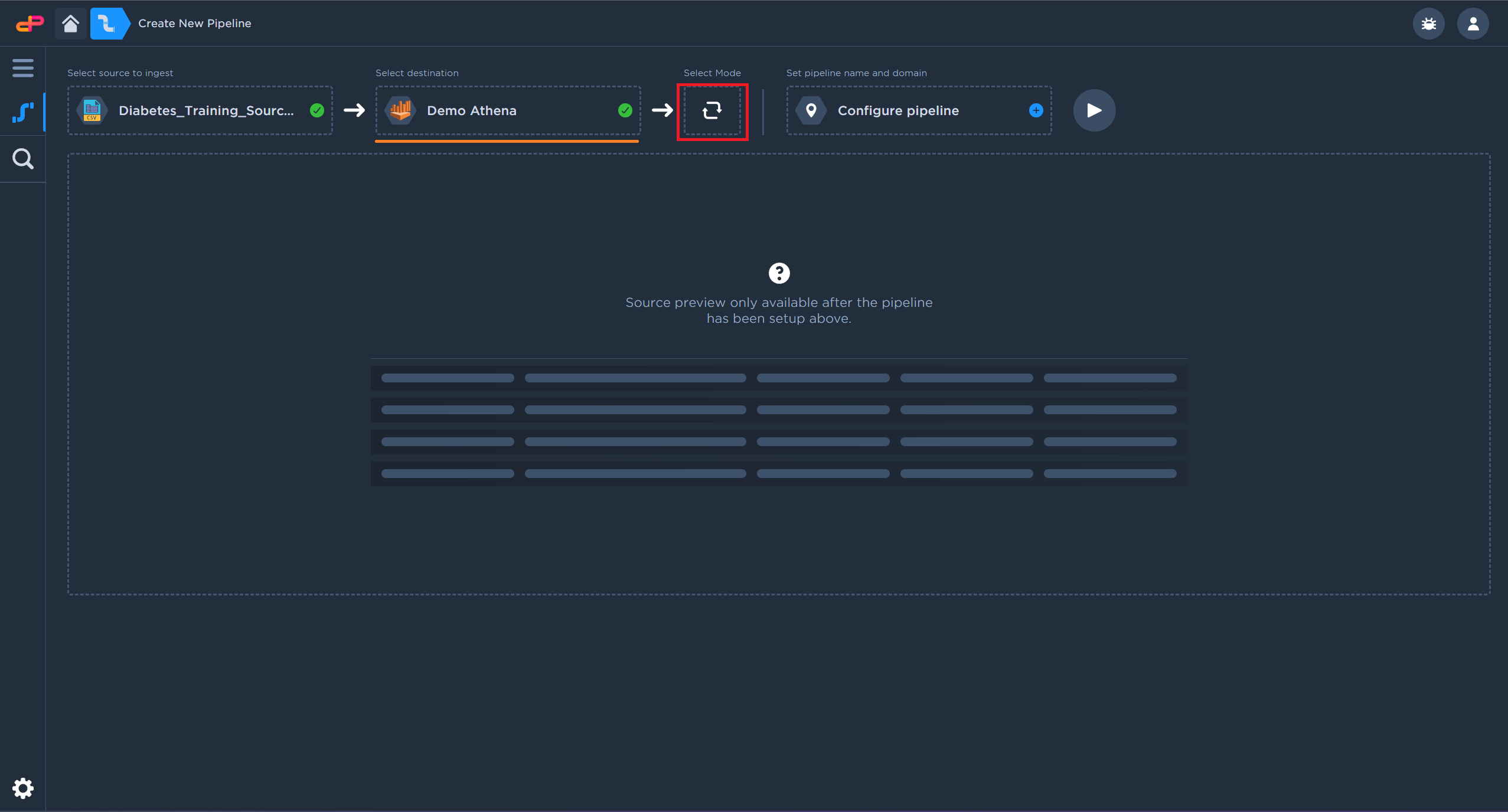
Click on “Select Mode”
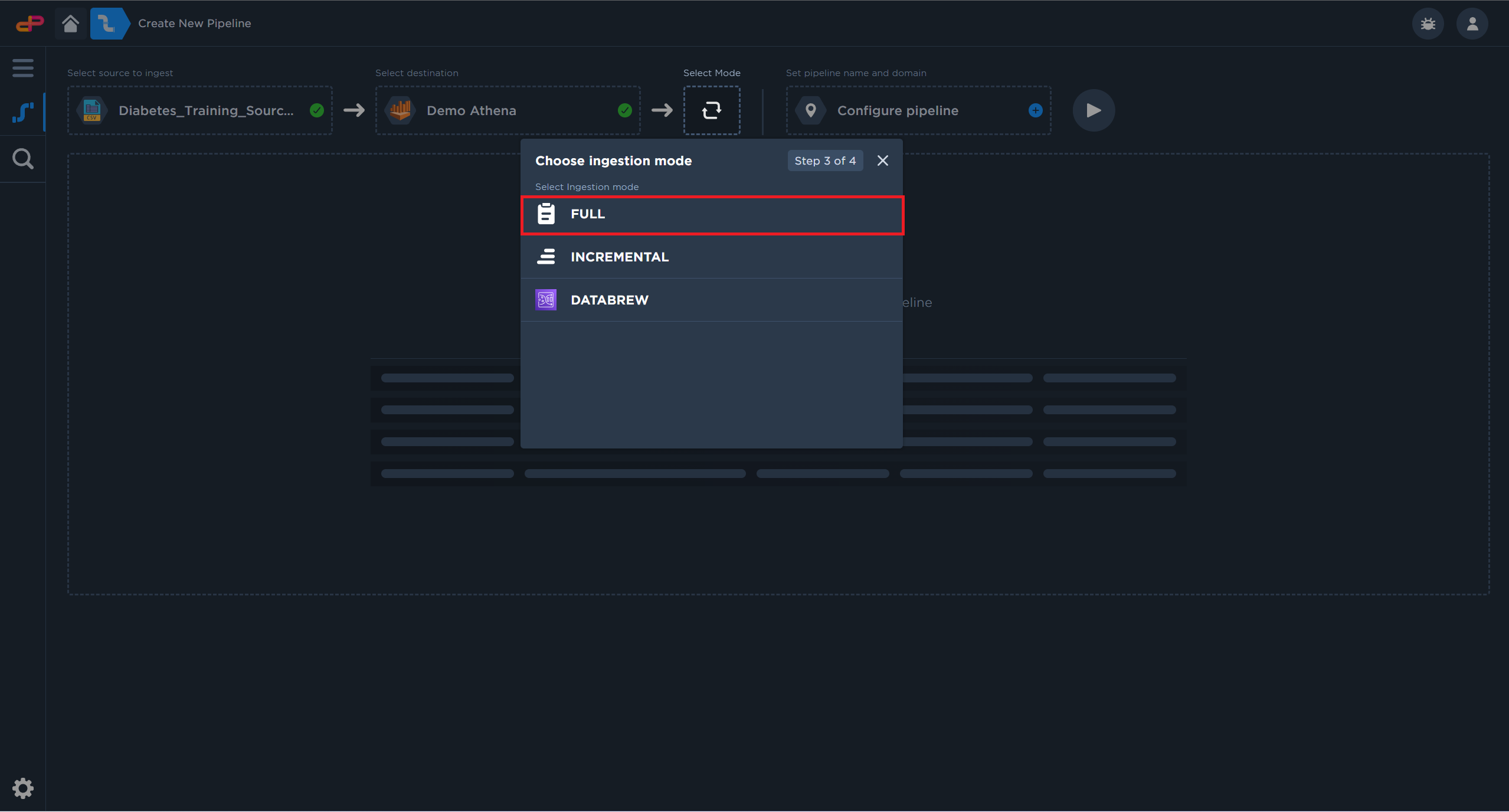
Select “Full” ingestion mode
Configure Pipeline Output Details
Click on “Configure Pipeline”.
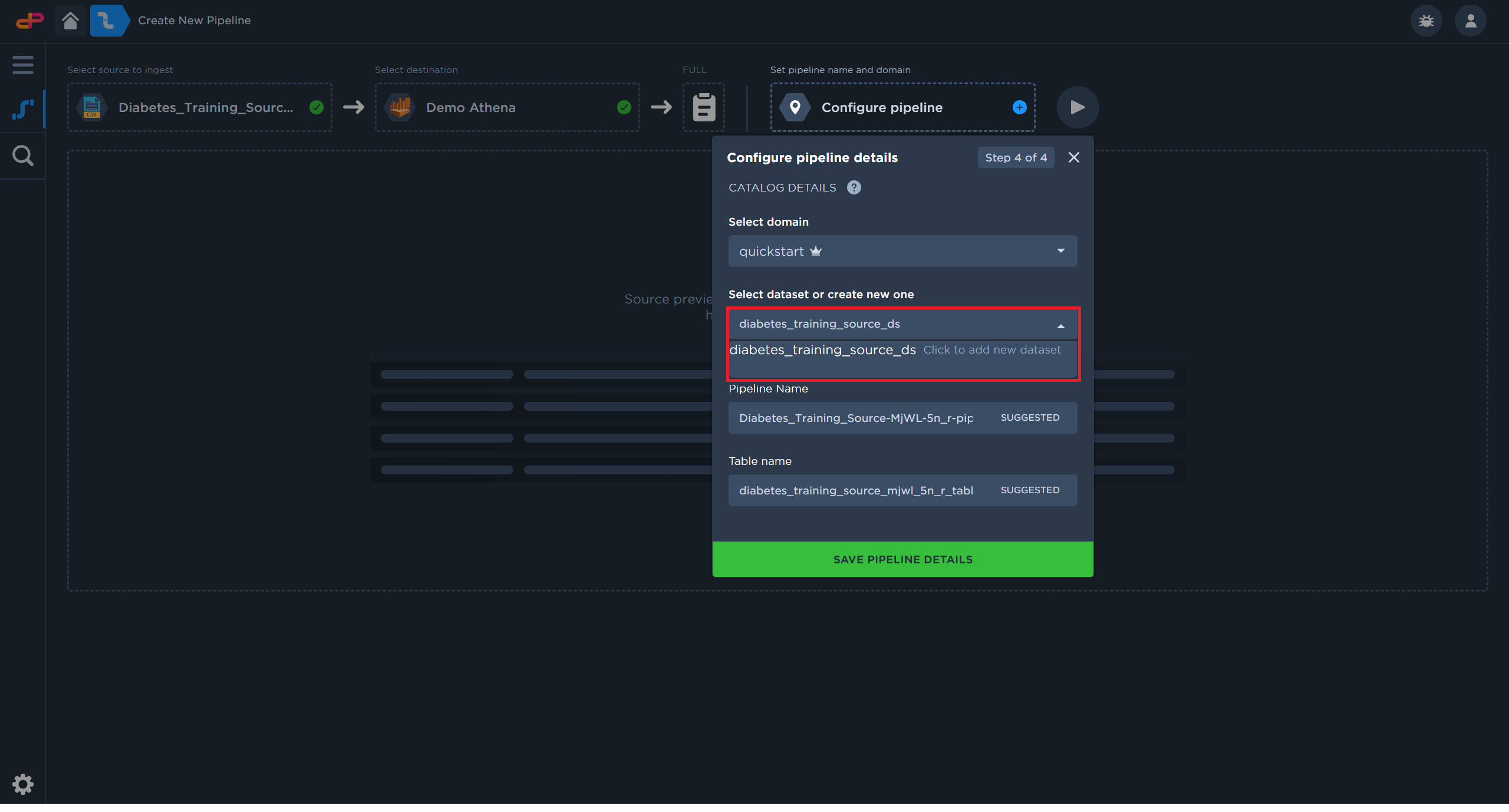
Create a new dataset.
[Optional] Modify the default table name for better searchability.
Save the pipeline details
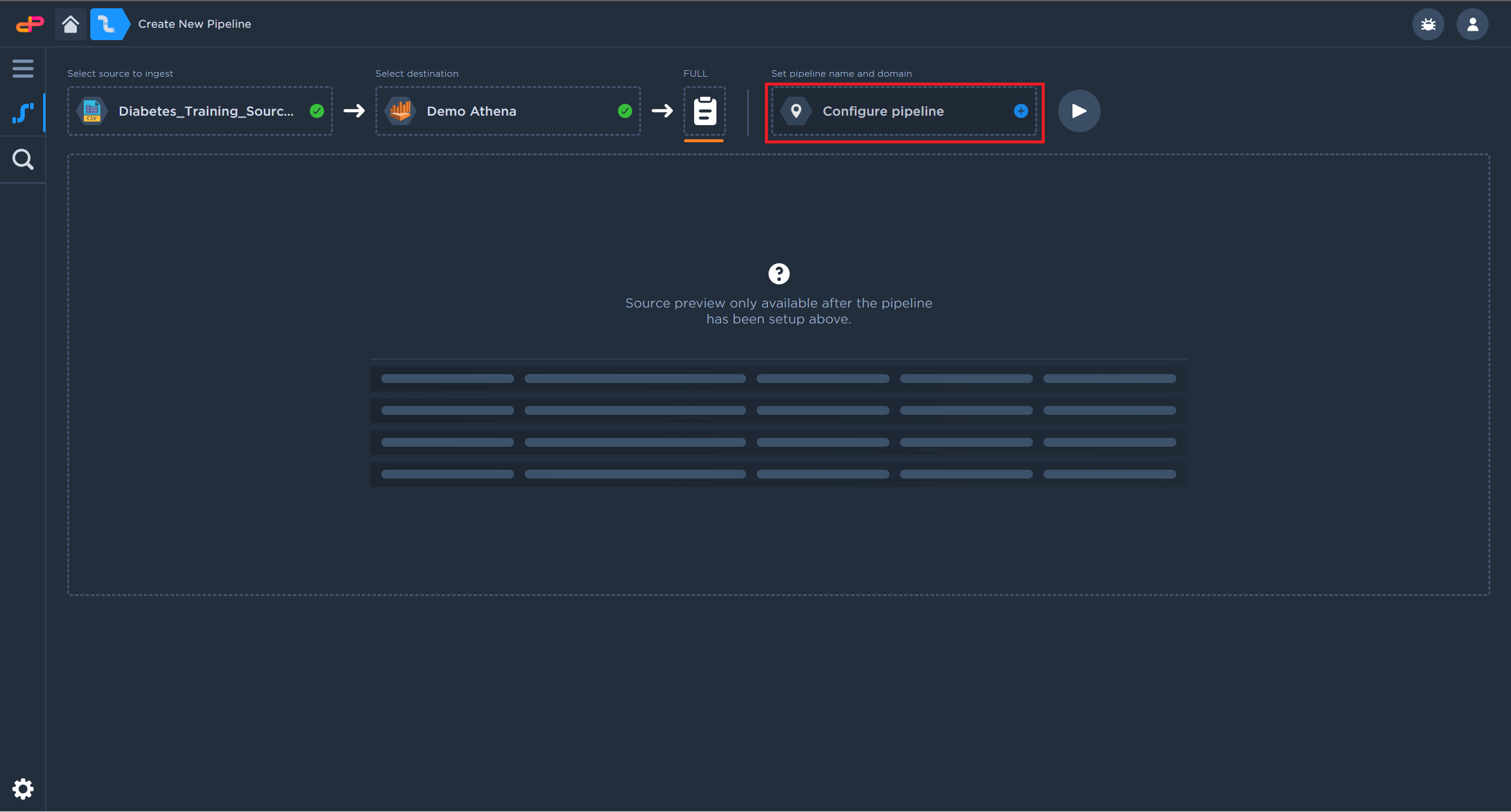
Click on “Configure Pipeline” to configure the data repository details
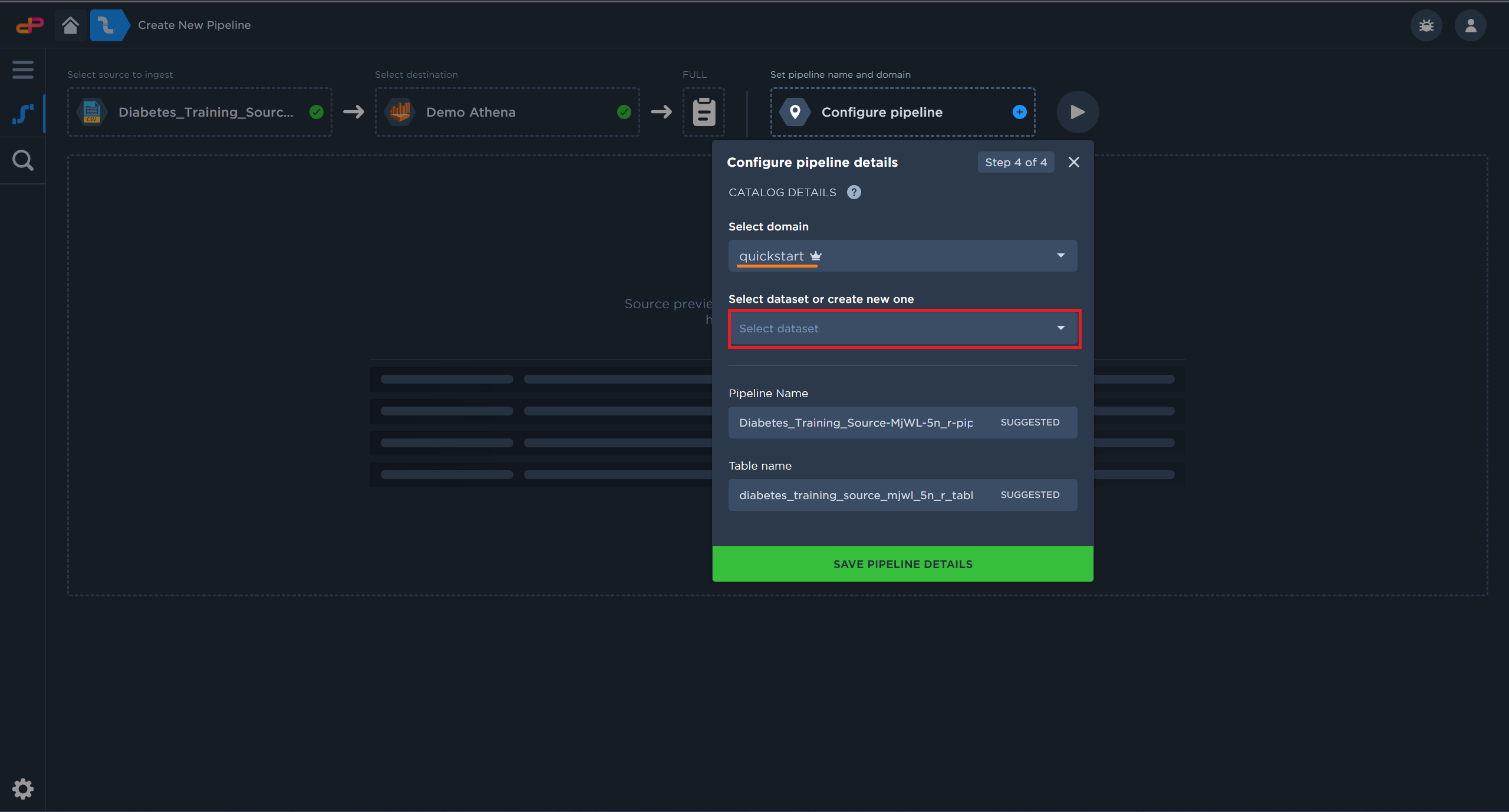
Create a new dataset by clicking on the dataset field
Click on “Save Pipeline Details”
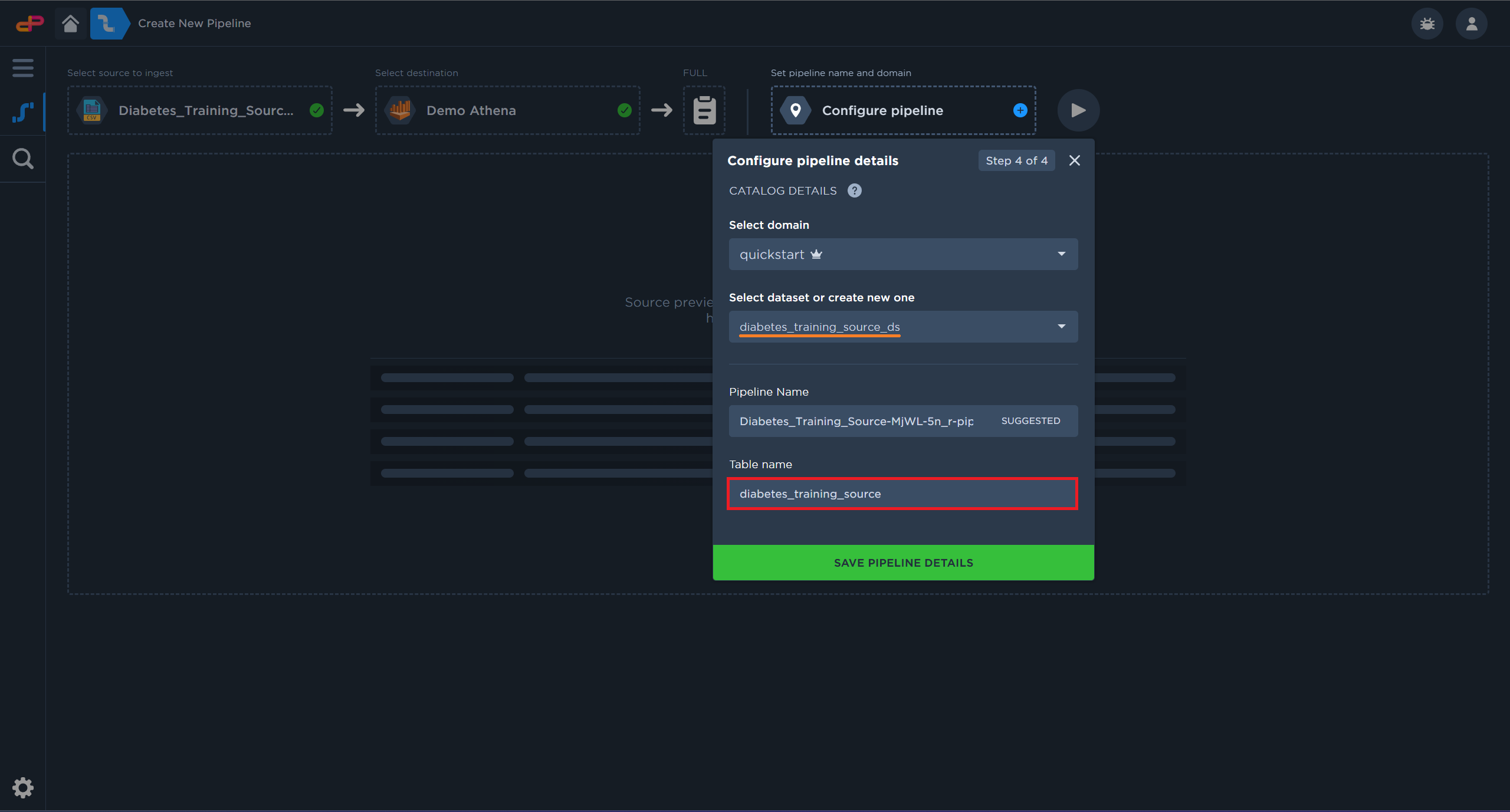
[Optional] Modify the default table name improves searchability.
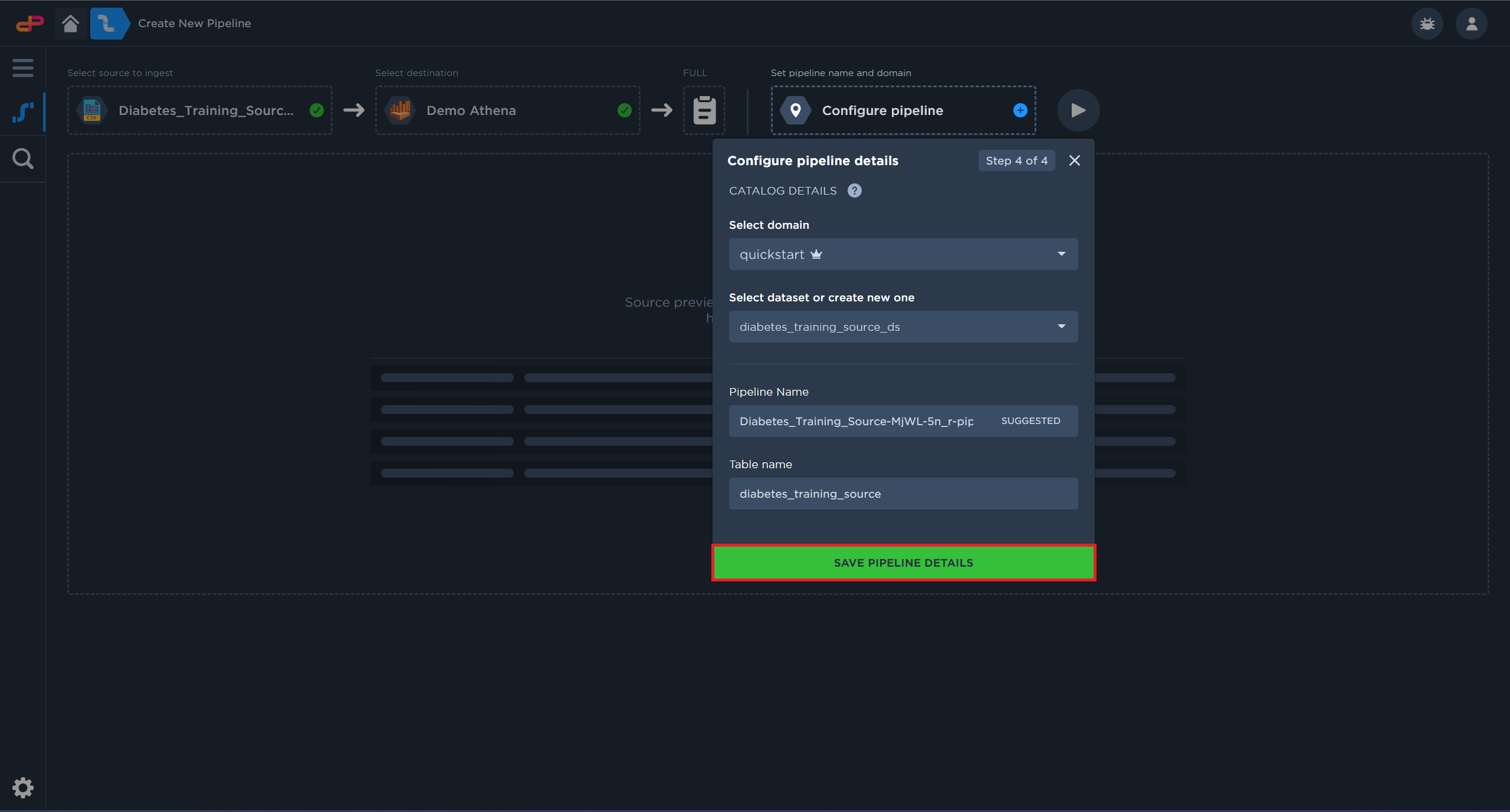
Click on “Save Pipeline Details”
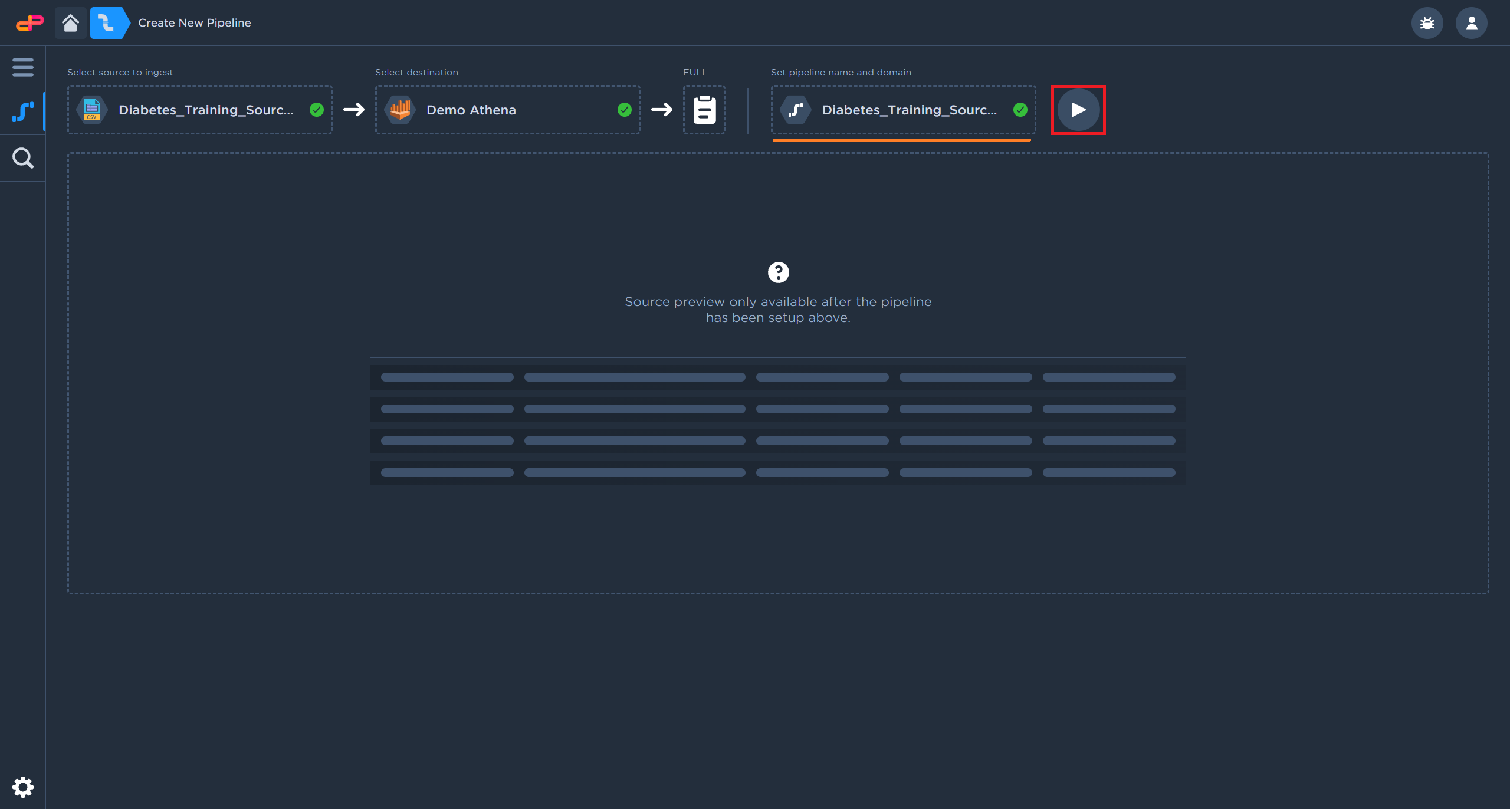
Click on the “Next” button to confirm the pipeline details
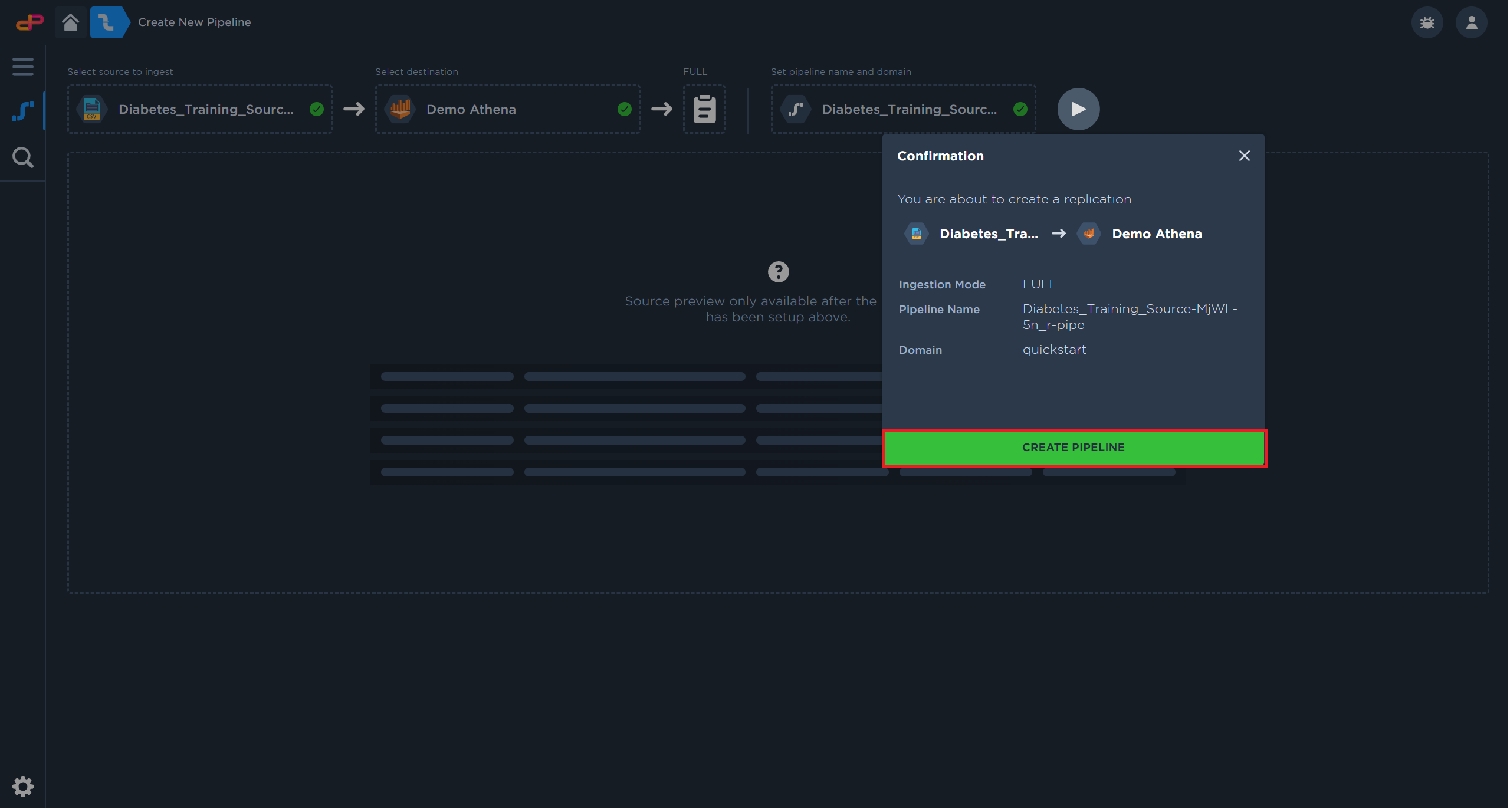
Click on “Create Pipeline” to create the pipeline
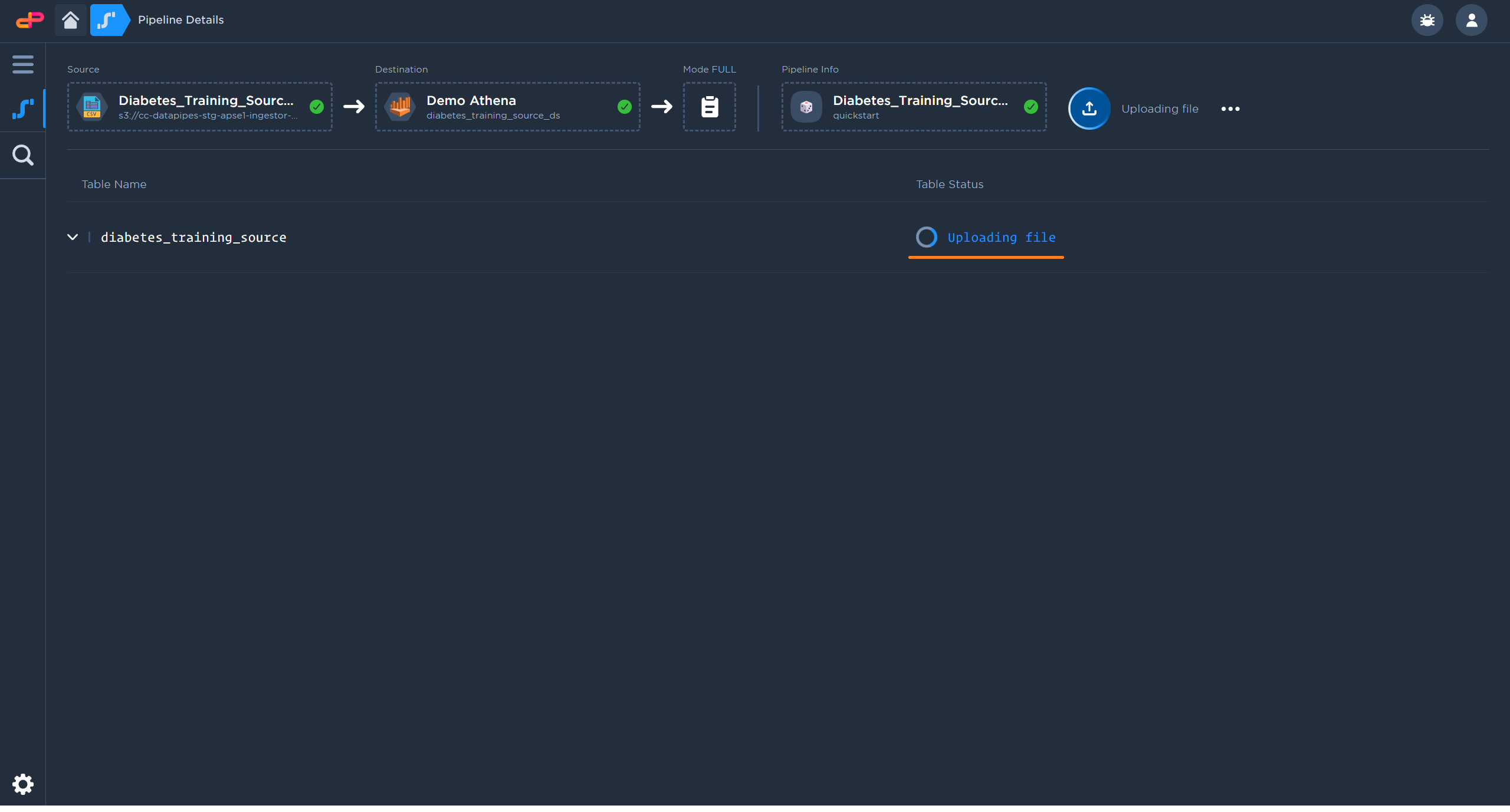
The pipeline will begin the file upload shortly after creation
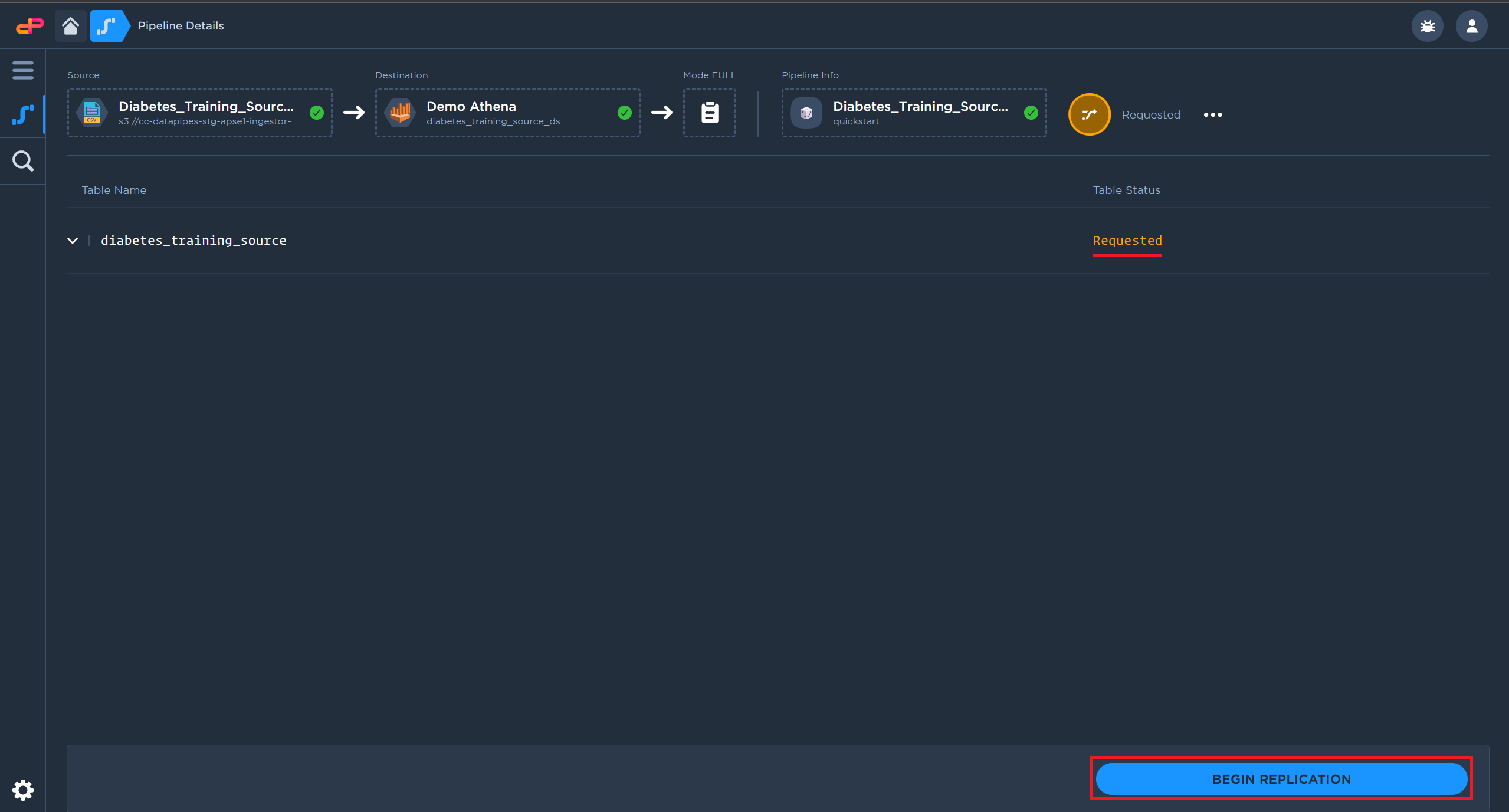
After upload completes, click on “Begin Replication” to push data into the destination
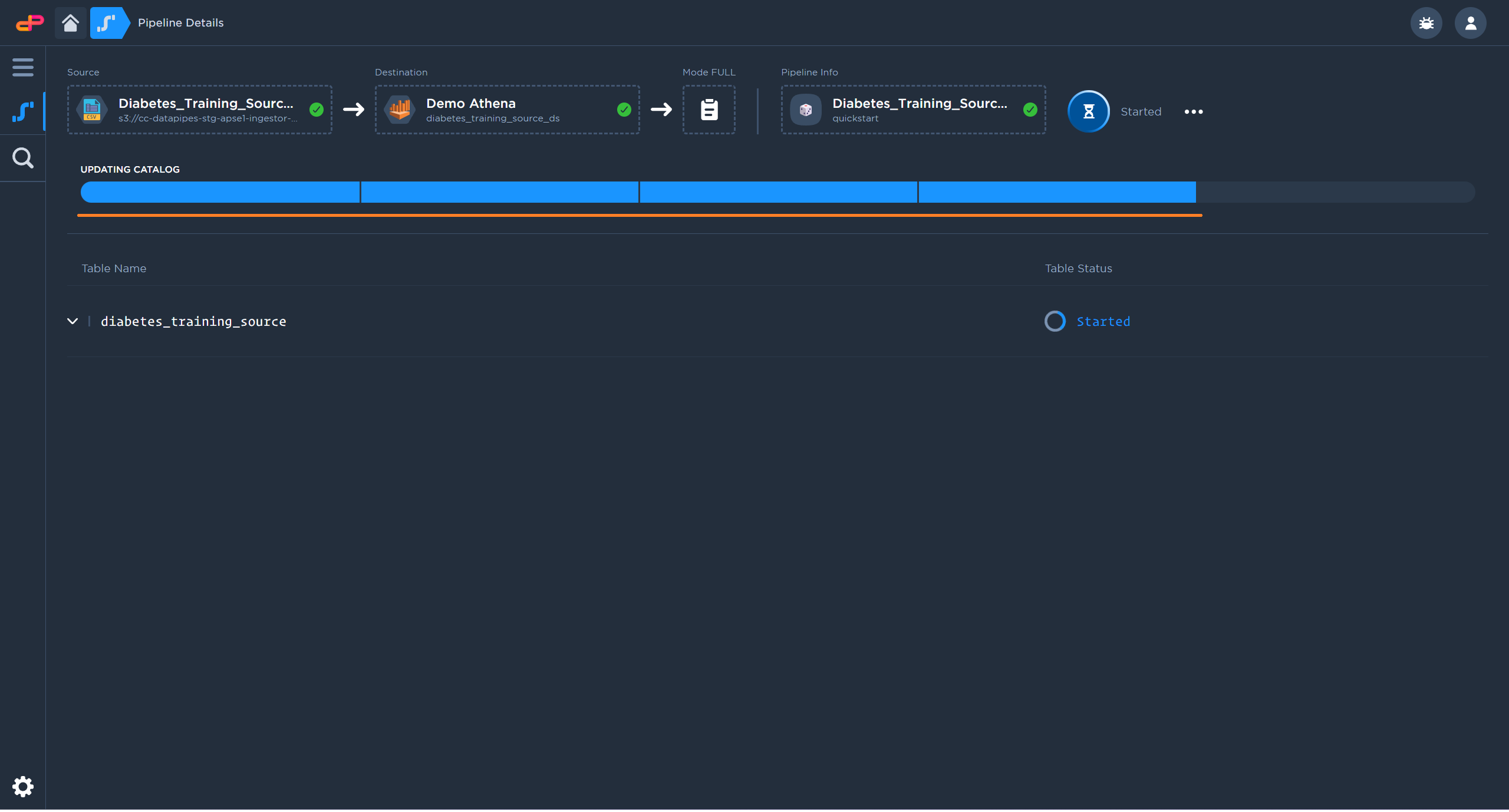
Depending on the file size, replication may take a while to complete
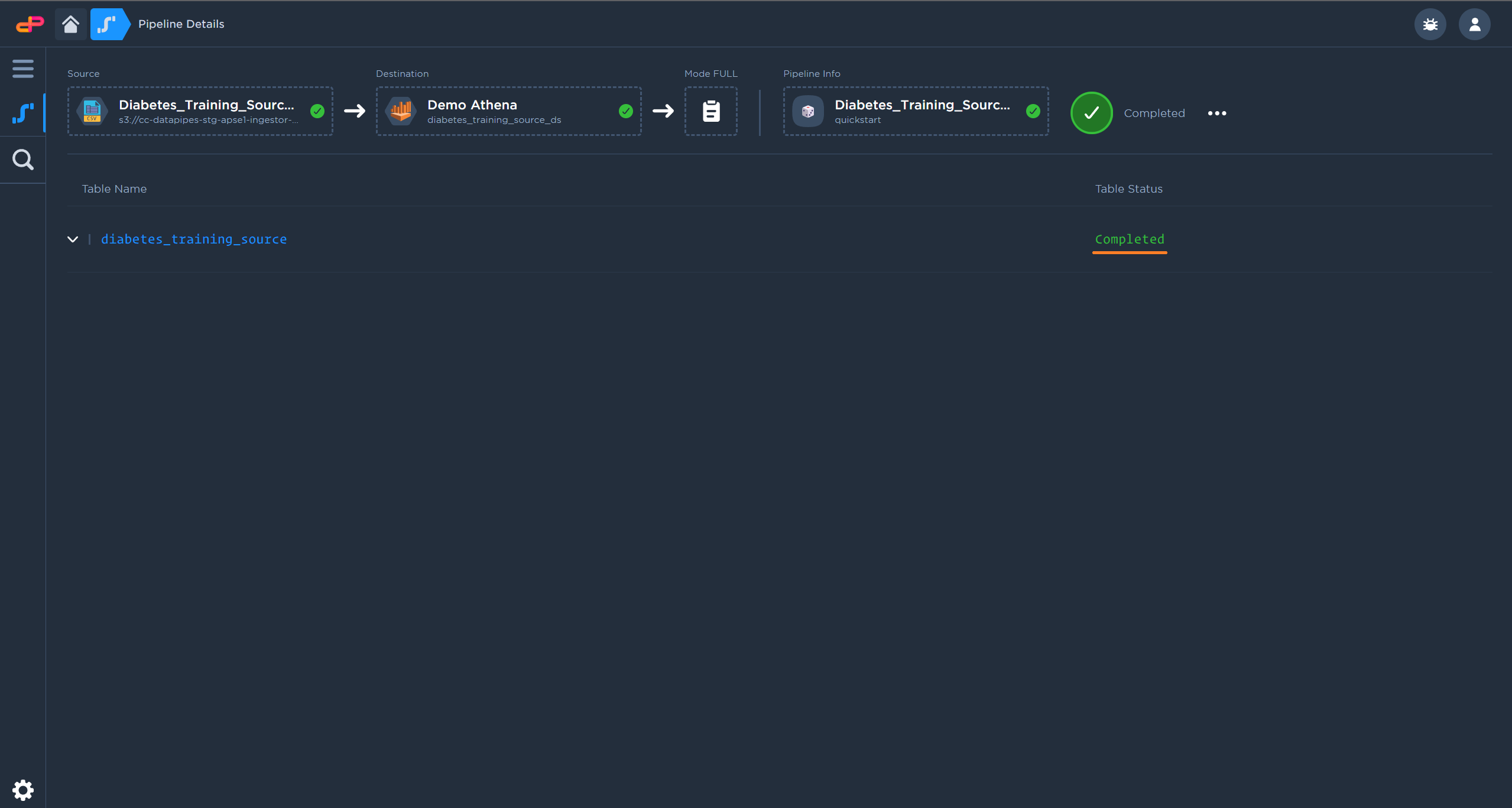
After the replication is completed, the data table will be available in the data catalog