
PII Scanning and Masking
Data Pipes scans and identify the PII related data from any source. Before replicating or ingesting the data into the data lake, Data Pipes runs a PII scan on the source which specifies what all columns have been identified as PII. In the case that PII columns are found, Data Pipes presents the results, which the user can take an action on whether they want to mask or tokenize the data. Data Pipes currently supports 2 techniques on handling PII data:
Masking: In masking strategy, the column data is replaced by asterisks ***, and hence that information/data becomes masked for the end user.
Tokenization: In tokenization, Data Pipes uses SHA-256 encryption to encrypt the data before ingesting into the data lake.
Mechanisms mentioned above will encrypt/mask the data at rest. This makes it irreversible operation.
PII scanning is currently supported during the time of data ingestion.
Select the source for replication.
Select the destination to which the data is to be loaded.
Configure the pipeline as shown below in different replication options.
Upon starting the replication:
PII scanning: It first runs the PII scan to identify any personal information associated with the data.
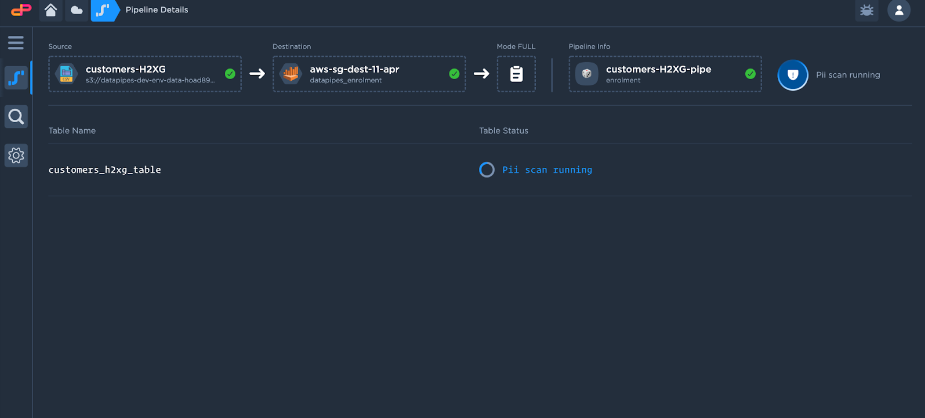
PII Results: Once the scan is completed, the following screen appears with the results of PII data.
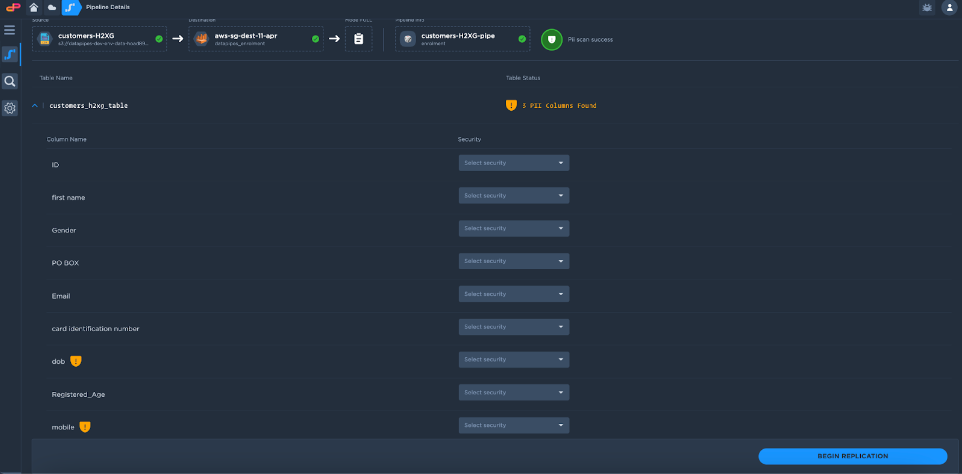
PII action: One can select the option of Masking and tokenization from the security dropdown.
Once the PII action is taken on the column, that column will be masked and tokenized and hence the actual data of that particular column won't be visible to the end user.